Anatomy of a live deployment
23 Mar 2024You have dockerised your web application, and now it’s time for the world to see it. What does that look like?
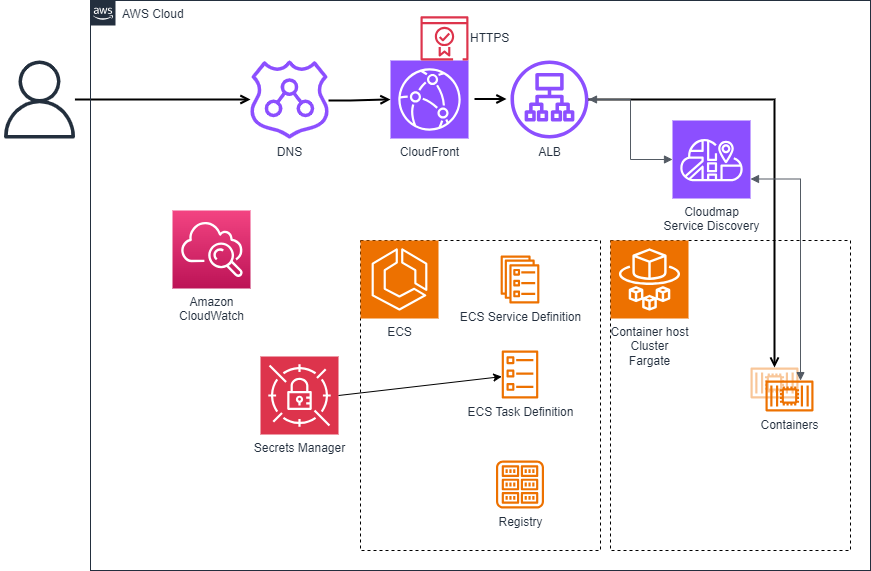
Production, what it looks like in AWS

You have dockerised your web application, and now it’s time for the world to see it. What does that look like?
Production, what it looks like in AWS
You might of heard about my latest award DevOps Professional of the Year 2024 if you follow me on LinkedIn.

Neil Millard, DevOps Professional of the Year
Do you have goals? How are you progressing with them?

GOALS to get you what you want - Image by Tumisu @ pixabay
A technical post today. Setting up Static Website with Terraform
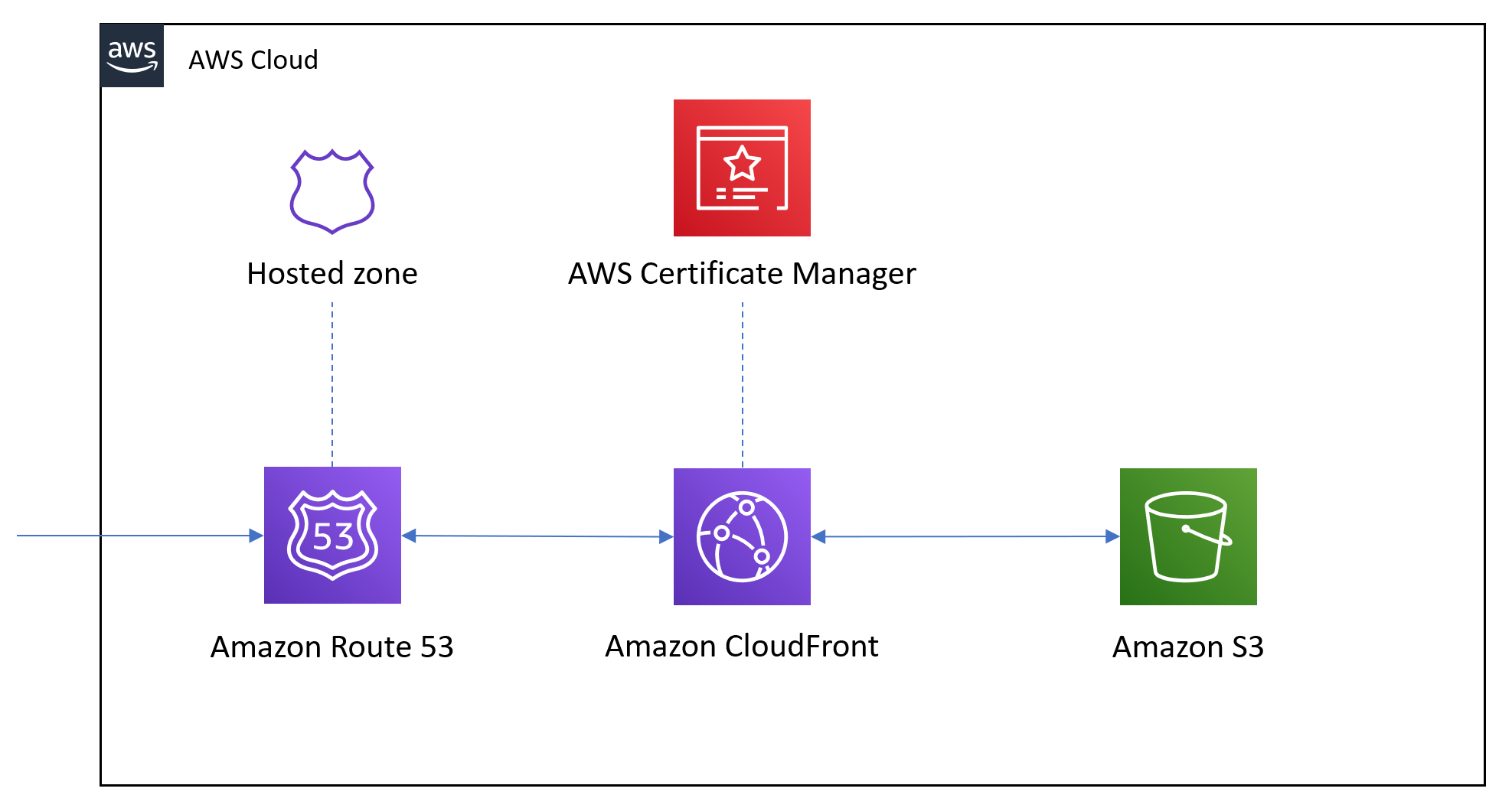
CDN?
Being confident is knowing you’re scared, but not showing everyone else.

Scared of Public Speaking?