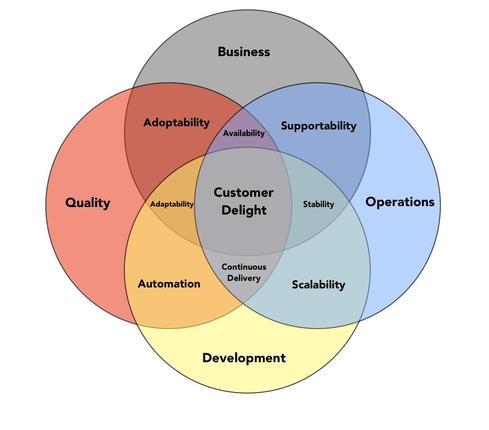
My Four Steps for a successful cloud deployment - Introduction
11 Jan 2019

I was asked to speak at an event, Expert Talks, in Manchester. This was originally scheduled before the summer break, but some football event was happening on the some night.
(Read more...)