
persistent data for docker and the cloud
18 March 2017 · Filed in InfrastructureThere are two types of data when we talk about computing, non-persistent or temporary data, and persistent data.
Non-persistent
Temporary data has a sliding scale also,
- a random number for a decision in an online game; required but lasts less than a second,
- a session ID for tracking your login details on a website; usually lasts for the length of that session, upto about 30-45 minutes,
- the contents of a shopping basket at an online shop; amazon keeps this for days, even years.
![]()
If any of these are lost, it isn’t much hardship and new data can be quickly recreated.
Persistent
Persistent data is intended to have a much longer life and is usually difficult to regenerate
- Banking transactions,
- Customer records in a Customer Relationship System (CRM),
- Your photos uploaded to cloud storage.

Where does the data live?
This has an obvious impact on the immutable server pattern, where the life of a server is short, a server is deployed, and when it is not required or some configuration or software update occurs, a new one is deployed and the old one is destroyed (Blue/Green deployment). The first question I am usually asked when I describe this pattern is, what about the data? Where does it go or come from? This is especially relevant when I use 9-5 servers. They don’t exists at all outside business hours. This can also be applied to an application running in a Docker container. There are three places where this data can be stored.
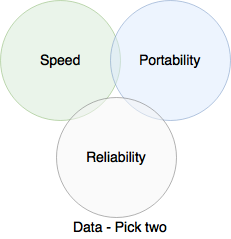
- On a backup device or storage, like AWS S3. This is slow to access, however is very portable and reliable. The data stored here would normally be copied to where it can be accessed. When a webserver front end is built, this would hold the configuration and static files of the web application.
- On a shared data server, that is accessible by the ‘compute’ servers at run time. They access the data across the network. This is a bit faster, portable and reliable. This issue here comes down to which server is hosting the data. You could have a Network File System (NFS) server, however, you may end up with a ‘pet’ on your hands. I have discussed Pet servers in my post about pets and cattle.
- On the server itself, this is restored from a backup location, then managed on the server or cluster. With this choice, you are picking Fast, Reliable, but not portable. Some applications will support the portable side of things for you, but this is very much at the application design level. If it does not support it, we have to use third party tools to do it.
To show you what I mean, lets have three examples.
Wordpress
 The most deployed open source website management system at the moment, is wordpress.
This software works well as a single installation, but scaling it can be a real pain. The biggest issue is the fact that wordpress stores data about the website locally on the webserver. If you have more than one web front end, they will quickly become out of sync. You upload a file for your blog, it only stores it on one of the servers.
Wordpress does have a number of plugins where we can tell it to use S3 as a shared data location, however the configuration files are still held locally for each server. For this data, NFS could be used as an online shared data source, however you may end up with a Pet server. This can be avoided by using another AWS server Elastic File System (EFS).
The most deployed open source website management system at the moment, is wordpress.
This software works well as a single installation, but scaling it can be a real pain. The biggest issue is the fact that wordpress stores data about the website locally on the webserver. If you have more than one web front end, they will quickly become out of sync. You upload a file for your blog, it only stores it on one of the servers.
Wordpress does have a number of plugins where we can tell it to use S3 as a shared data location, however the configuration files are still held locally for each server. For this data, NFS could be used as an online shared data source, however you may end up with a Pet server. This can be avoided by using another AWS server Elastic File System (EFS).
Databases
 The biggest headache for database administrators is Input/Output Operations (IOPS). To get a fast response from the database, the data it reads needs to be a close as possible. This rules out the shared network option detailed above.
Several database systems will work in a cluster, sharing and distributing the data amongst the nodes. Software like MySQL, MongoDB and CouchDB support synchronising between distributed nodes to scale out the deployment, with CouchDB having it a central design goal.
These systems support the adding and removing of nodes (supporting failures and replacements) whilst keeping the data safe and consistent. However you will find some data lag, eventual consistency.
The biggest headache for database administrators is Input/Output Operations (IOPS). To get a fast response from the database, the data it reads needs to be a close as possible. This rules out the shared network option detailed above.
Several database systems will work in a cluster, sharing and distributing the data amongst the nodes. Software like MySQL, MongoDB and CouchDB support synchronising between distributed nodes to scale out the deployment, with CouchDB having it a central design goal.
These systems support the adding and removing of nodes (supporting failures and replacements) whilst keeping the data safe and consistent. However you will find some data lag, eventual consistency.
Docker
Data sync between docker containers is very much a problem still for this growing technology. Several solutions are in the works, ClusterHQ with Flocker, Portworx, Hedvig and StorageOS. I will be checking these out as I work through Dockerizing my customers full application stack. I have used BTSync with some success, which keeps the data in the container rather than on a hosted volume. This separates the data from the Docker Host (avoiding another pet).
What solutions have you seen? Are there any you’d like me to try out? Let me know in the comments below.
Previous Post: software design principles according to Neil Millard and John Romero Next Post: 6 steps to becoming a cloud expert Tags: cloud computing · data · docker · docker persistent data · immutable