
My Four Steps for a successful cloud deployment - Scale
1 February 2019 · Filed in Infrastructure Development BookScaling for flexible workloads
Another excerpt from my book, Who moved my Servers?

One of the most attractive features of moving to the Cloud is the ability to scale applications quickly based on workload.
This burst feature enables the systems to call on extra resources when needed, and possibly more importantly, release them once the demand drops so you’re not paying for servers to sit idle.
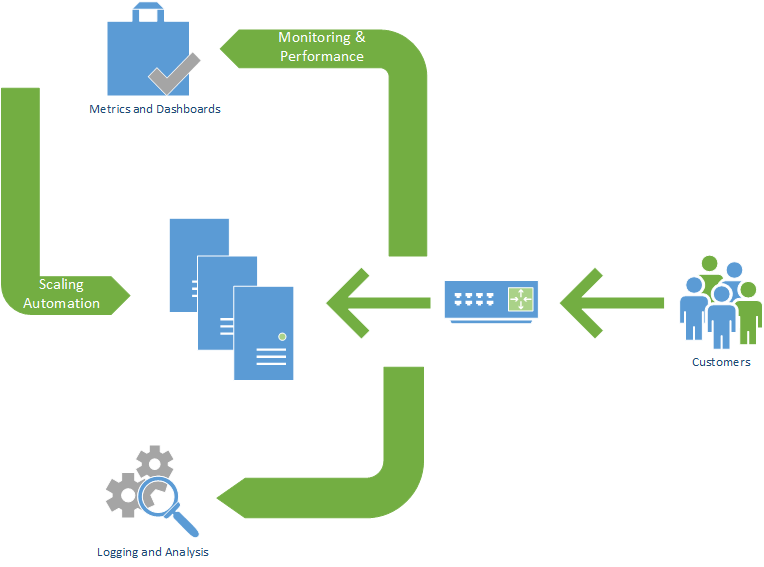
There are three parts to enabling this function for your application:
- Access points or load balancers
- Monitoring and automation systems
- Tuned metrics so control or trigger the automatic scaling up and down.
Access points or load balancers provide a clear point of entry to the application. For a webserver, this is what sits behind the website address, but in front of the webservers producing the web pages. Having a known entry point means the application can divert the request to wherever is best to deal with that action at that time.
As mentioned in the Axa web app scaling and load balancing case study, the application may need some awareness of the load balancer – so they work together. This may require some design and development time to ensure the APIs and microservices can reconnect (in the event a server disappears mid-query) or share data appropriately knowing the server is in a team.
The monitoring and automation systems are then made ready to enable multiple services to be created and destroyed based on demand automatically. Auto scaling is where the automation follows rules based on some metric describing the performance of the application, so that resources are added and taken away for consistent response times.
Scaling out and in relies on a rule. This rule is based on a metric, CPU usage, user requests, or memory usage. This metric must be chosen carefully for its ability to measure the load on the servers if it’s to increase service capacity when required.

Scaling out is easy – scaling in, however, is a little trickier. Servers and applications create data, either just logs and activity or new inputs such as photos or status updates. I will talk about data in a moment. The other thing that makes scaling in difficult is when to judge that the server is no longer needed or being access by your customers. A simple delay in the rule’s execution will help slow the automation so it doesn’t react to a sudden spike or drop in traffic, where the demand would have changed before the server can start or stop.
The load balancer will be able to stop traffic going to a server when it’s no longer needed – this is called draining connections. Once this is complete, the server can shut down. The application may also need modification to allow this, ensuring that a user connection doesn’t need to stay connected to any server specifically due to local data.
Next: Data
Who moved my servers. Available from Amazon in Paperback and Kindle now.